
話者識別
話者識別を実際に利用する方法は2つあります。ひとつは mimi API を直接実行する方法、もうひとつは mimi API Console 画面を操作する方法です。
ここでは、 mimi API Console 画面を操作して話者の識別を行う方法について説明しています。
説明文中には mimi の基本概念について で説明している概念が記載されています。mimi のサービスを利用するには、基本概念を理解しておくことが必要です。
1 : アプリケーション・クライアントの準備
話者識別を行うには、話者の名前や話者の音声を登録する必要があります。また、これらの情報は、アプリケーションおよびクライアントに紐付けるため、事前に話者識別が実行できるアプリケーション・クライアントの準備をします。
- アプリケーションの準備
- 話者識別が実行できるアプリケーションがない場合、アプリケーションの登録方法もしくは、アプリケーションの編集方法を参考にし、スコープ欄で話者識別を「実行」とします。
- クライアントの準備
- 任意のアプリケーションを選択し、クライアントの登録方法を参考にして、スコープ欄で話者識別を「実行」とします。mimi API Console 上ではクライアントの編集ができないため、話者識別が実行できるクライアントがなければ新規登録してください。
2 : 話者グループの作成
TOP画面で「話者識別 mimi SRS 」という項目の中にある「話者グループ」をクリックしてください。
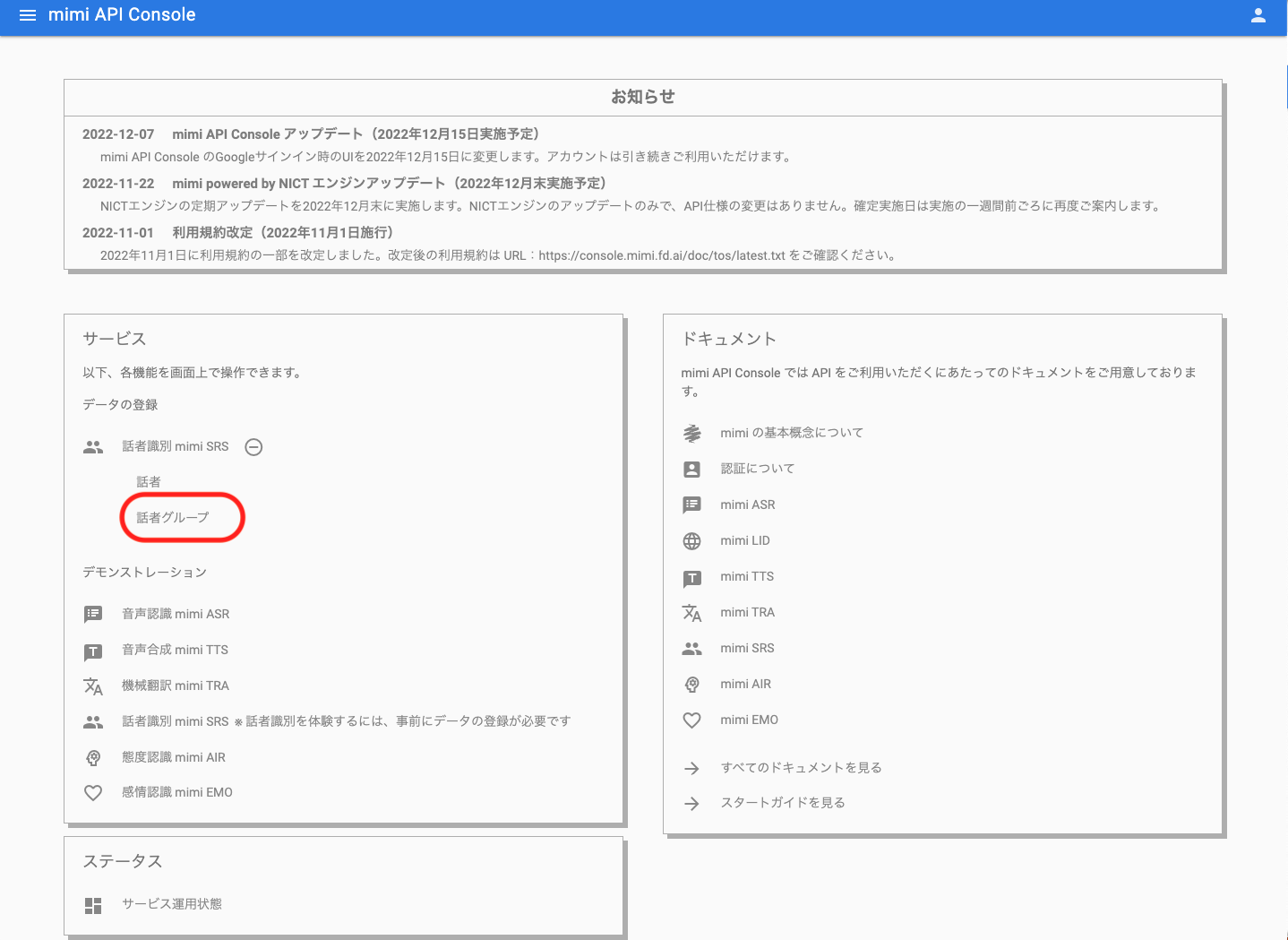
話者グループ一覧に遷移したら、話者グループの新規作成を行います。話者グループはアプリケーションに紐づける必要があるため、紐付けたいアプリケーション(例:test-app )を選択して「新規登録」ボタンを押下します。
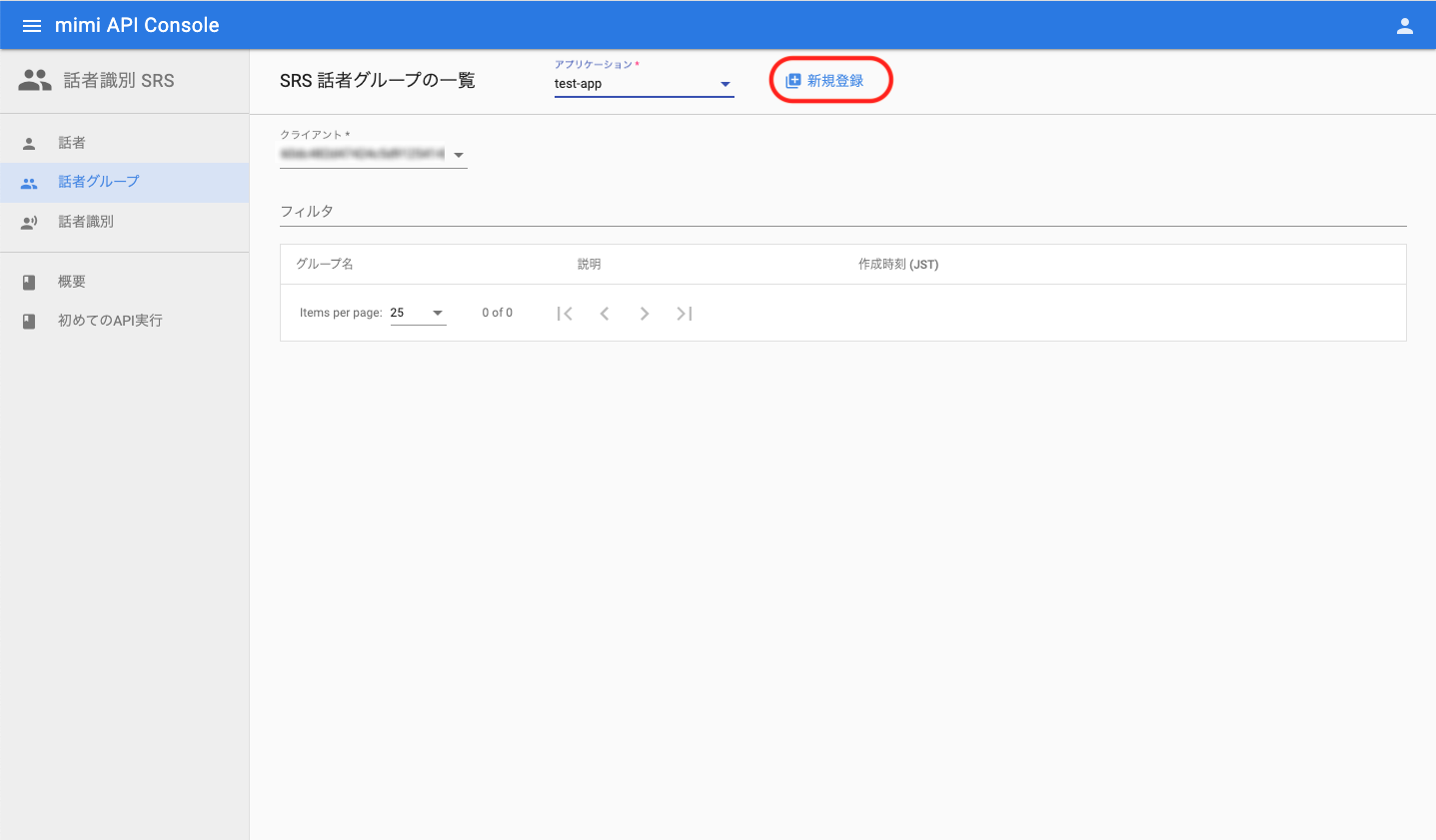
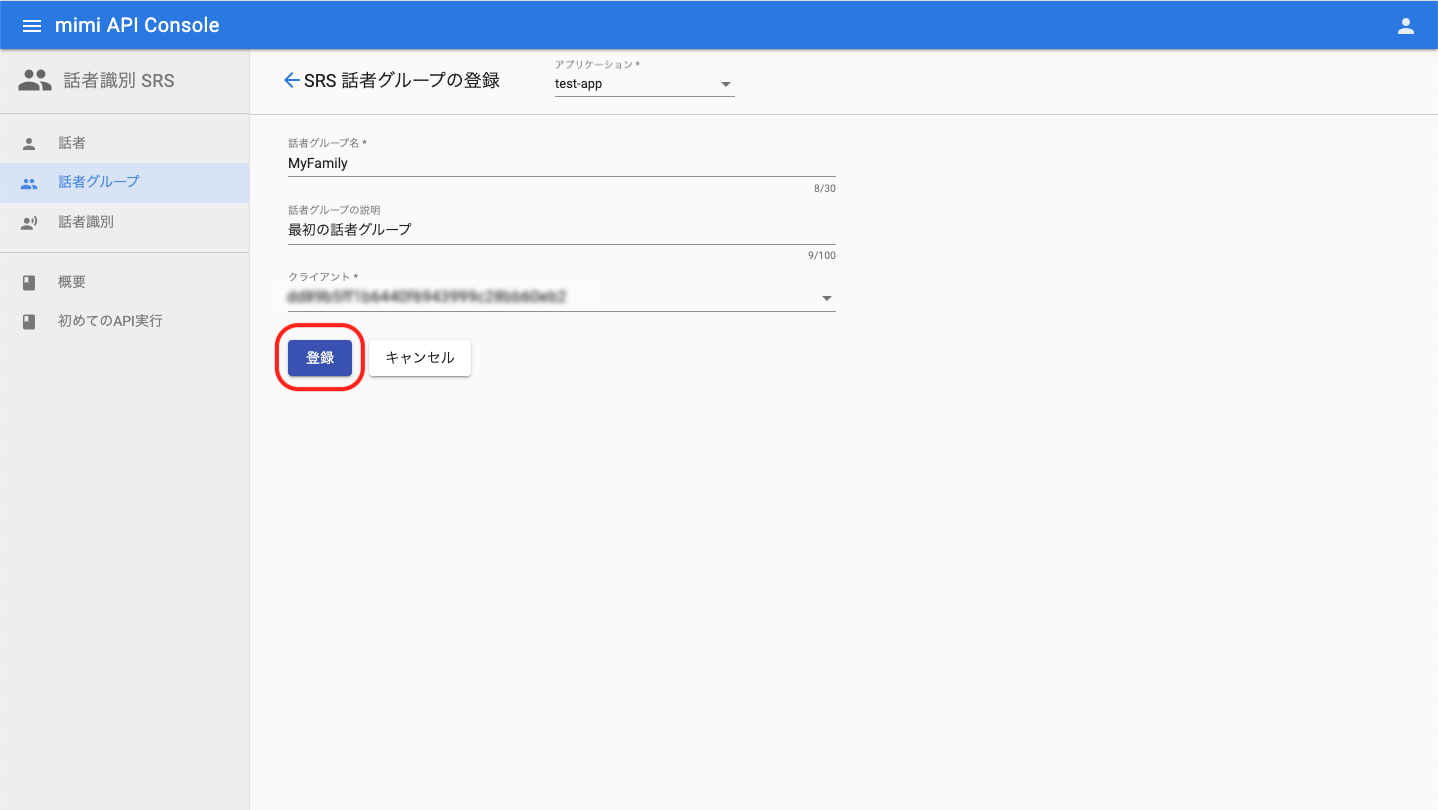
話者グループの登録画面でグループ名を入力し、「登録」ボタンを押下します。話者グループの詳細画面へ遷移したら、「所属話者」ボタンを押下して、話者の登録へと進みます。
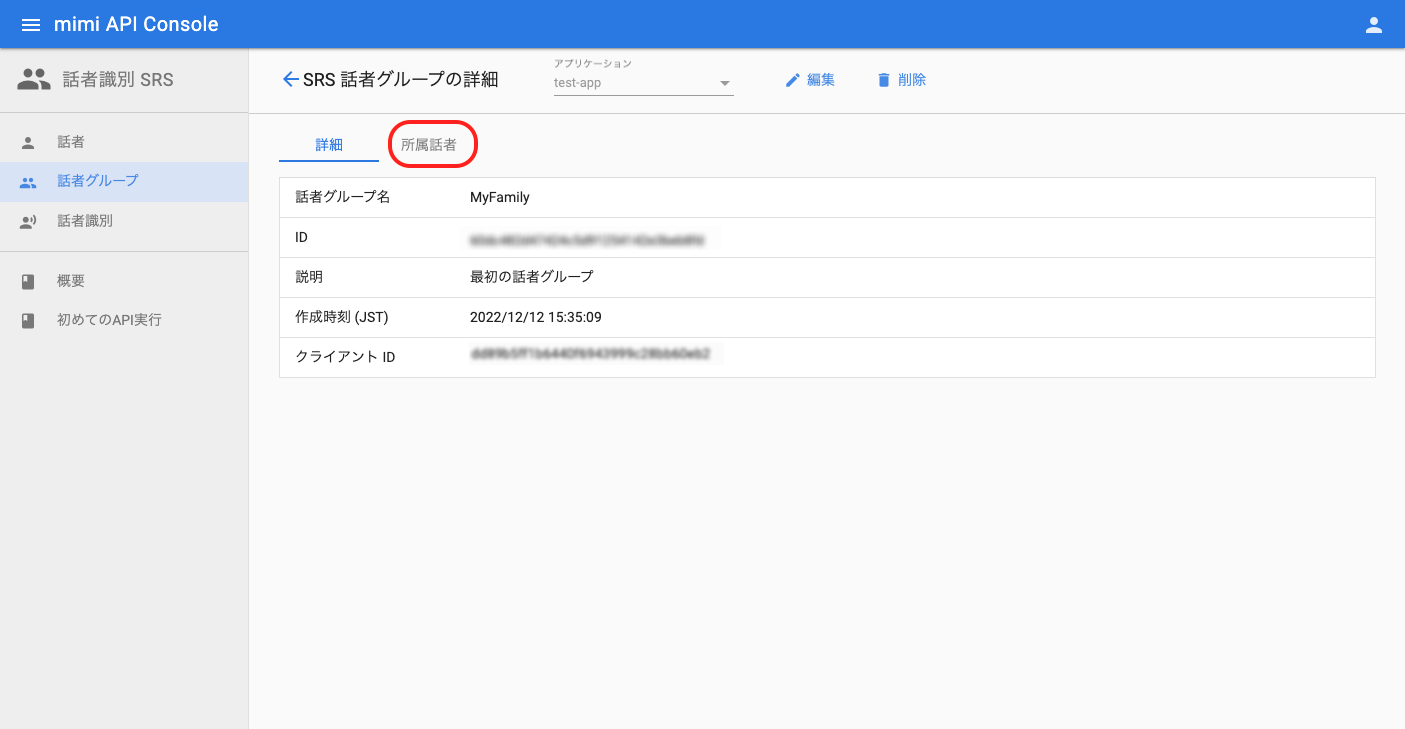
3 : 話者の登録と話者グループへの追加
話者を識別させるために話者を登録し、話者グループに話者を追加します。まずは、話者登録を行うために、所属話者一覧画面で「話者の登録」を押下します。
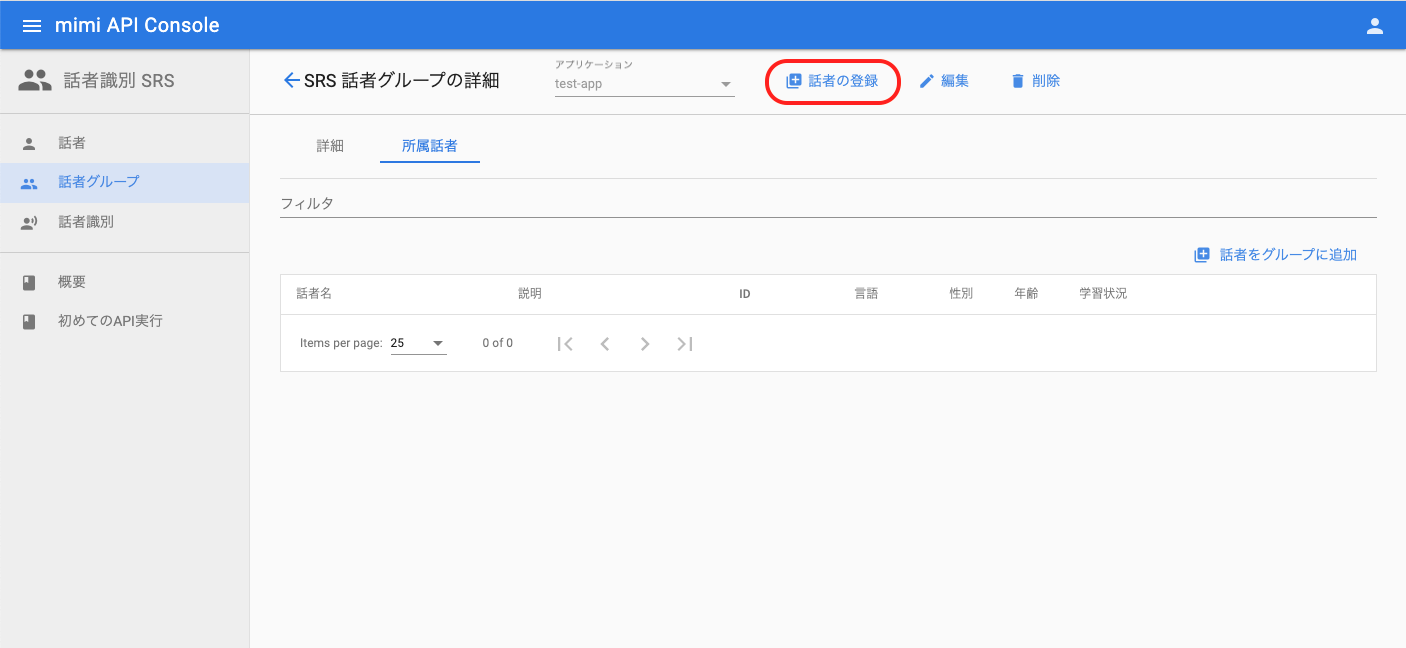
話者の登録画面へ遷移したら、名前、言語を指定して話者を登録します。
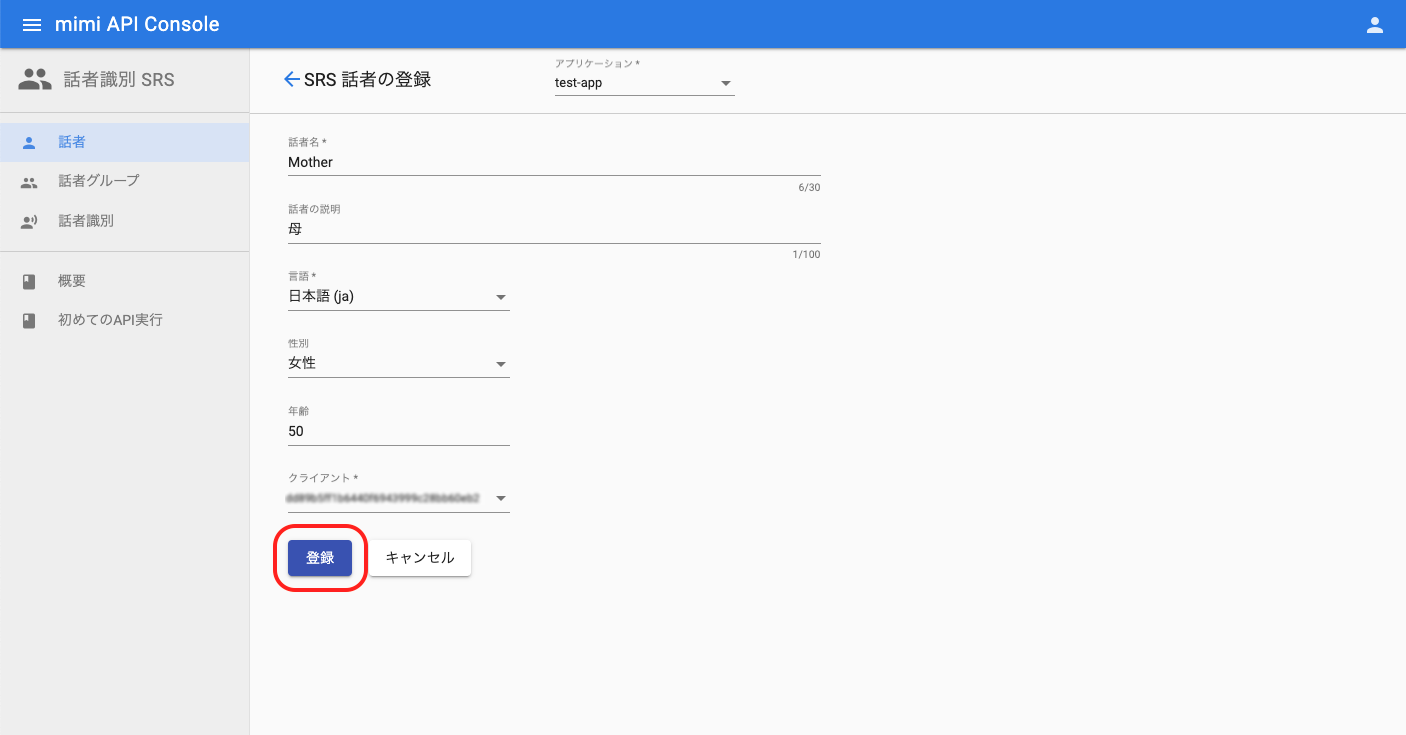
任意項目について性別、年齢の入力は任意です。ただし、これらは話者識別エンジンに対してのヒントとして扱われるため、登録することによって識別精度が向上する可能性があります。
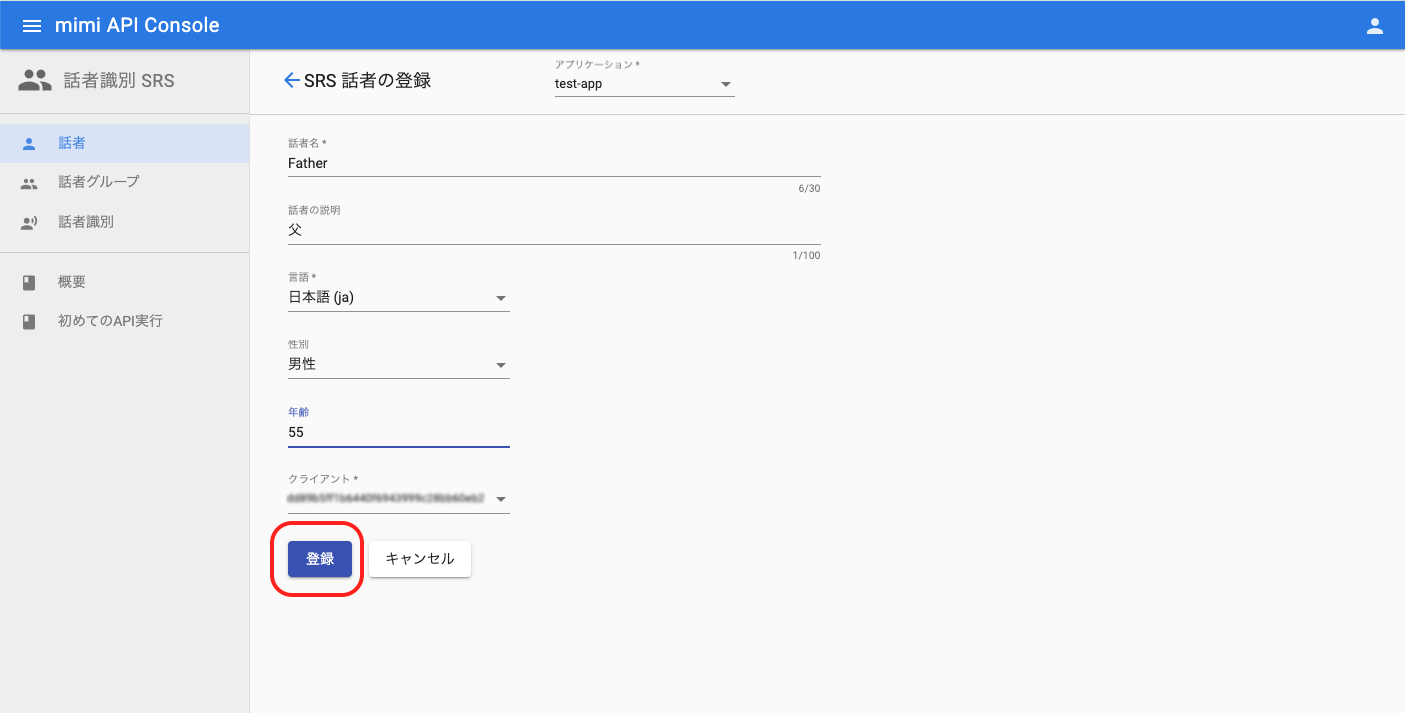
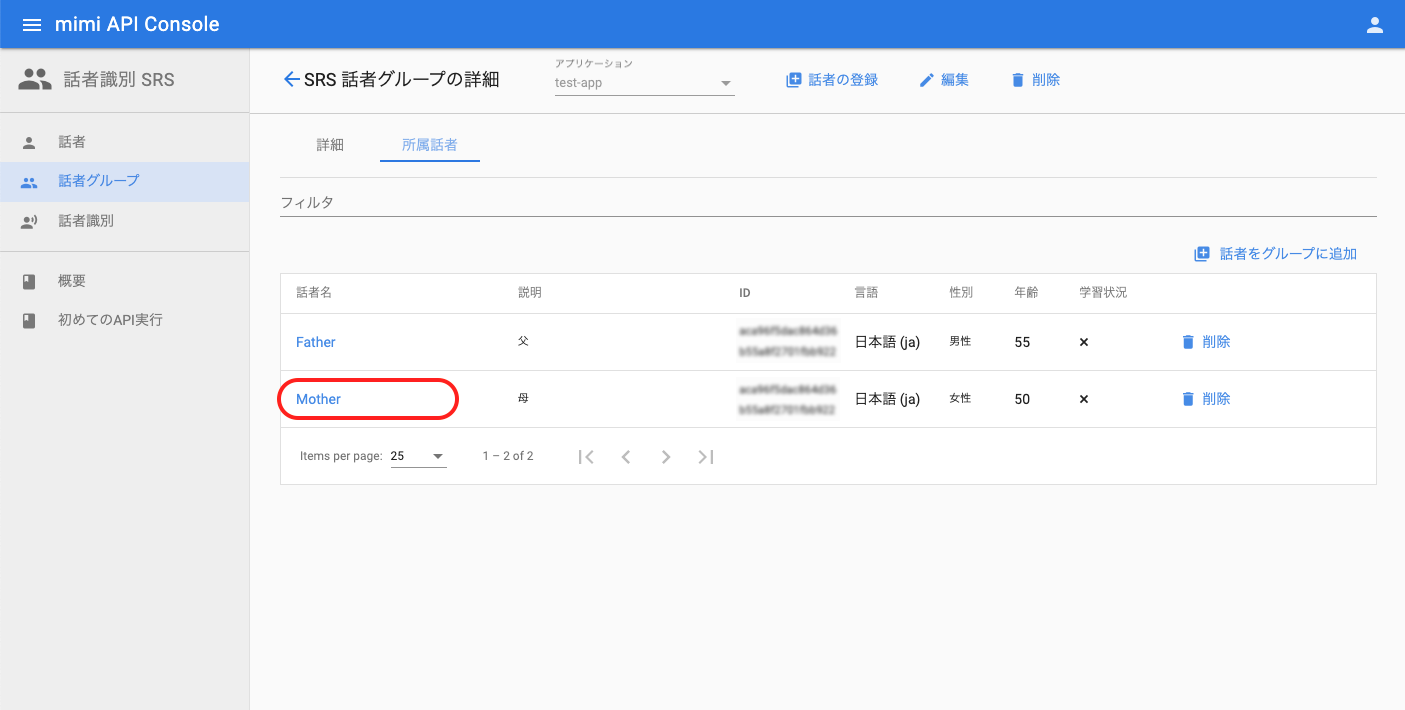
話者登録完了後は、再度話者グループの一覧へ遷移し、グループに対して話者の追加を行います。話者を追加したい任意のグループ(例:MyFamily )を選択してください。
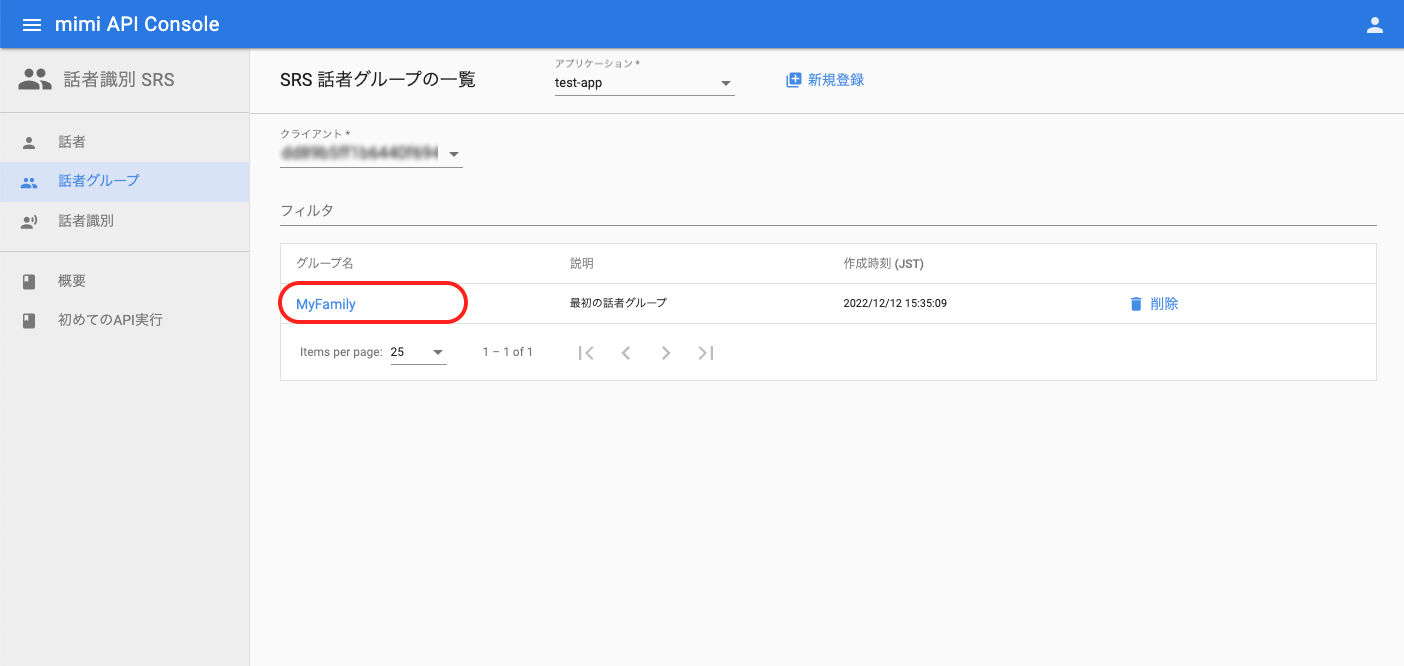
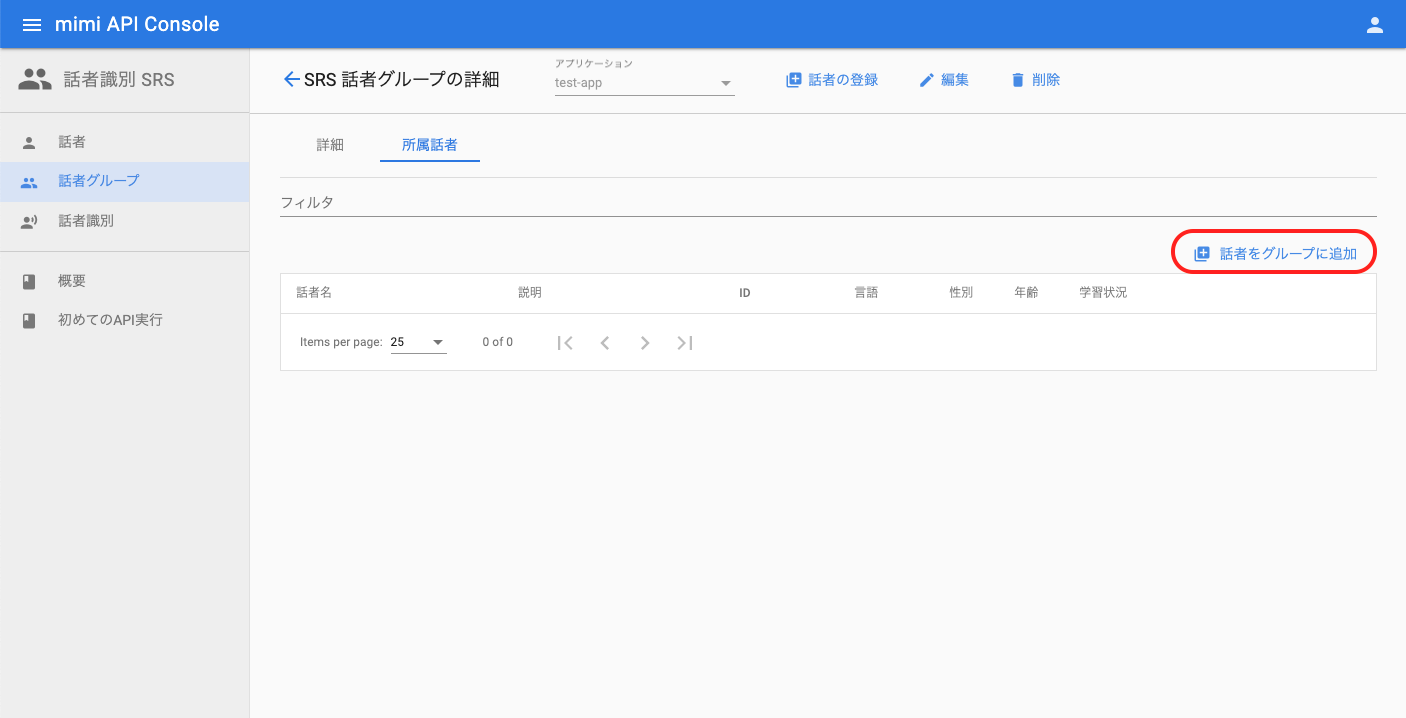
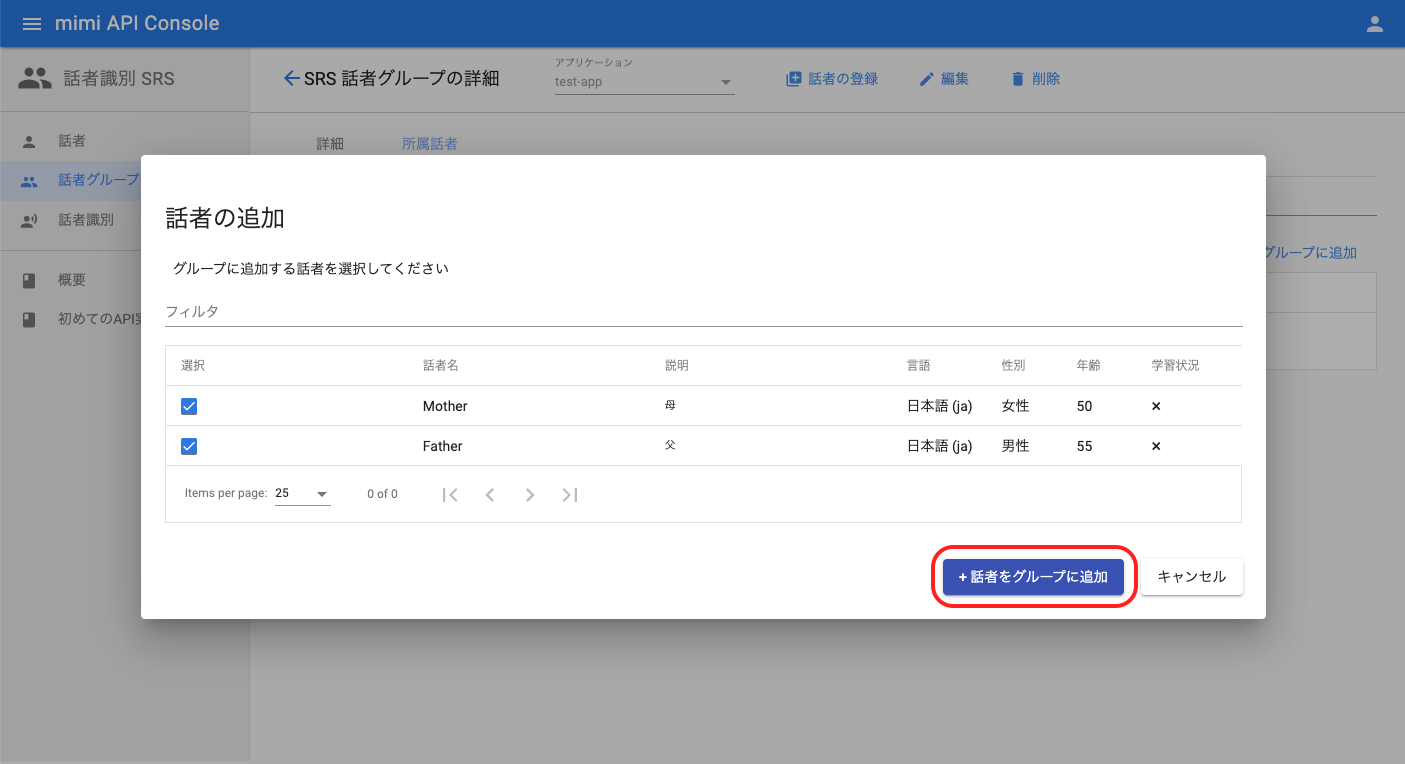
グループ詳細画面へ遷移したら、「話者をグループに追加」を押下します。話者の追加ダイアログが表示されたら、紐付けたい話者を選択して「話者をグループに追加」を押下します。
4 : 話者への発話データの登録(学習用音声の登録)と学習の実行
話者の登録が完了したら、話者識別を実行するために話者の発話データを学習させます。話者一覧から任意の話者(例:Mother )を選択してください。
話者の詳細へ遷移したら、「学習」を押下して音声データの登録を行います。登録は「マイクで録音」か「ファイルアップロード」で行うことができます。
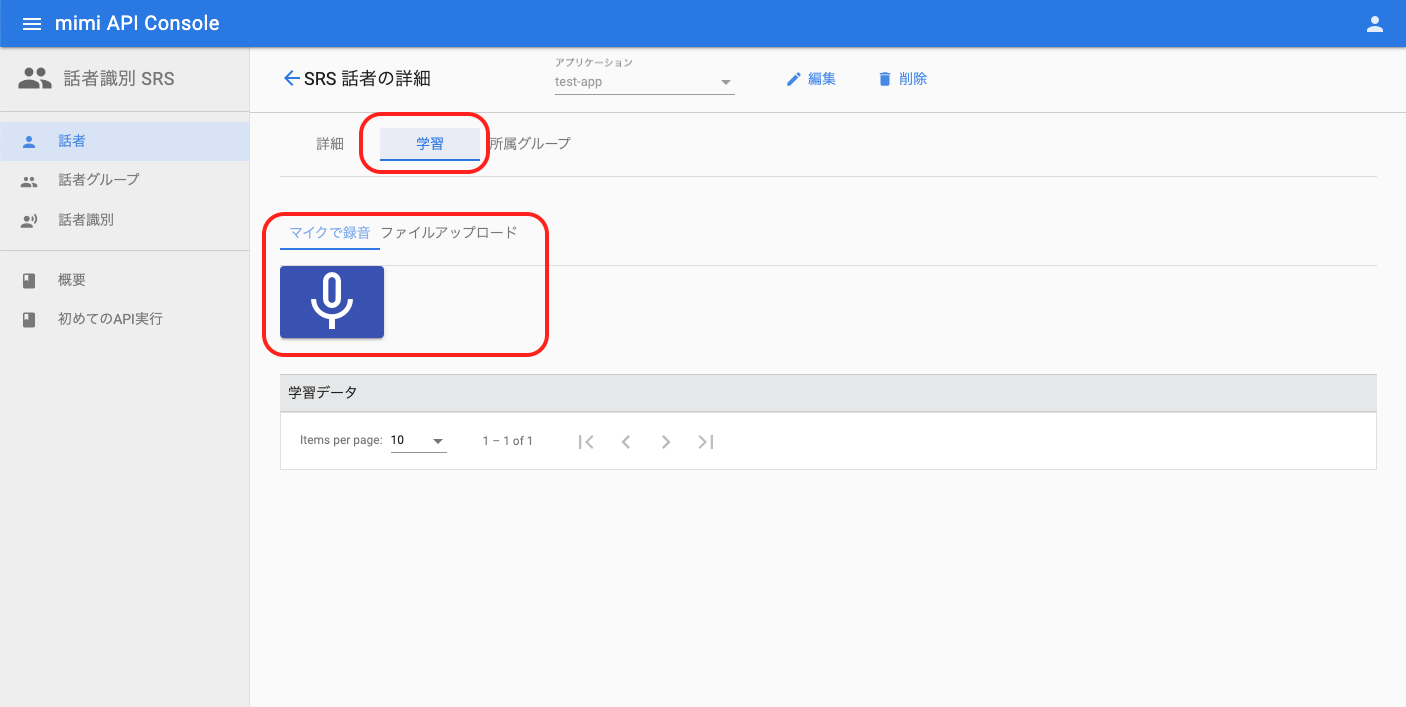
1 つの音声データにつき、学習データが 1 つ作成されます。これを繰り返して、複数の音声データを一人の話者に対して登録・学習します。
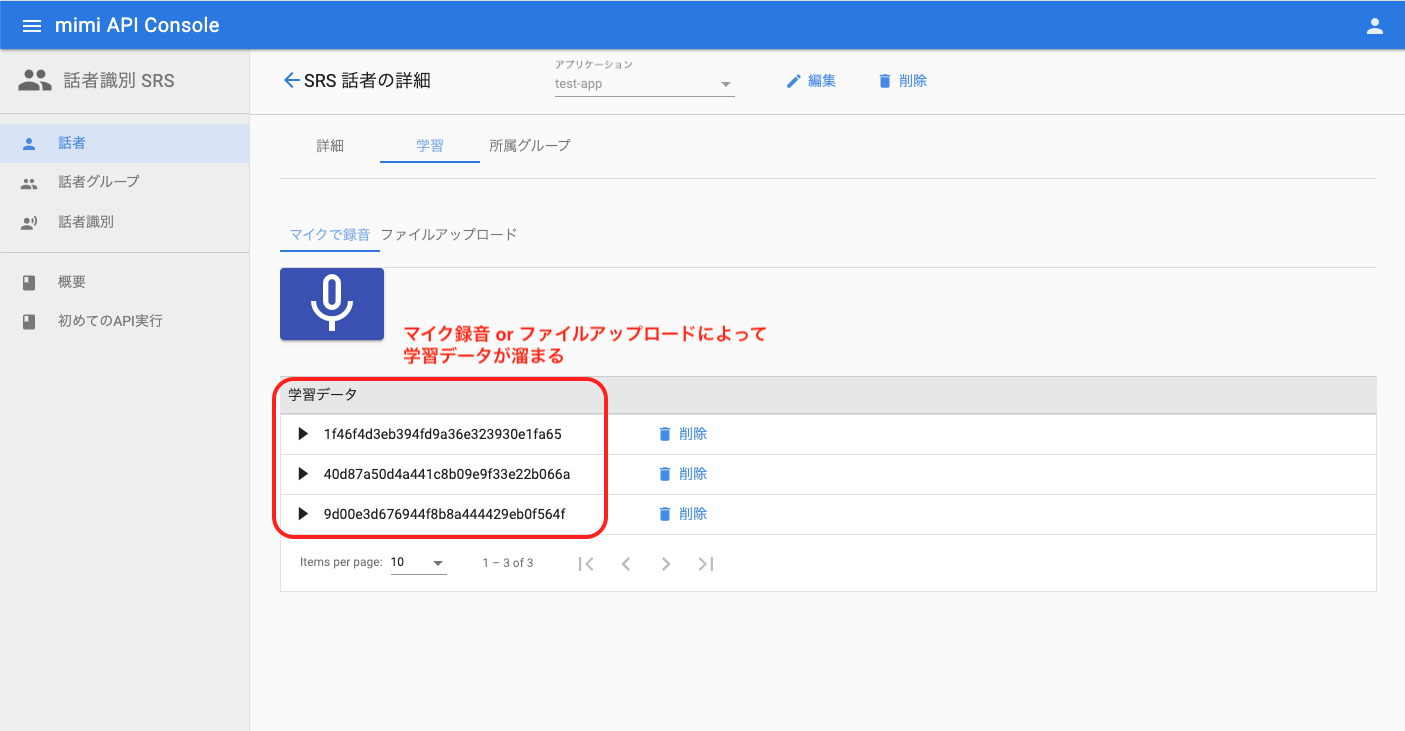
話者の詳細で、学習状態が「○」になっていれば学習完了です。そうでない場合は、さらに音声データの登録を行うようにしてください。
また、この学習は話者グループに追加されている話者全てに行うようにしてください。この例だと MyFamily に追加されている Mother、Father 双方学習完了とする必要があります。
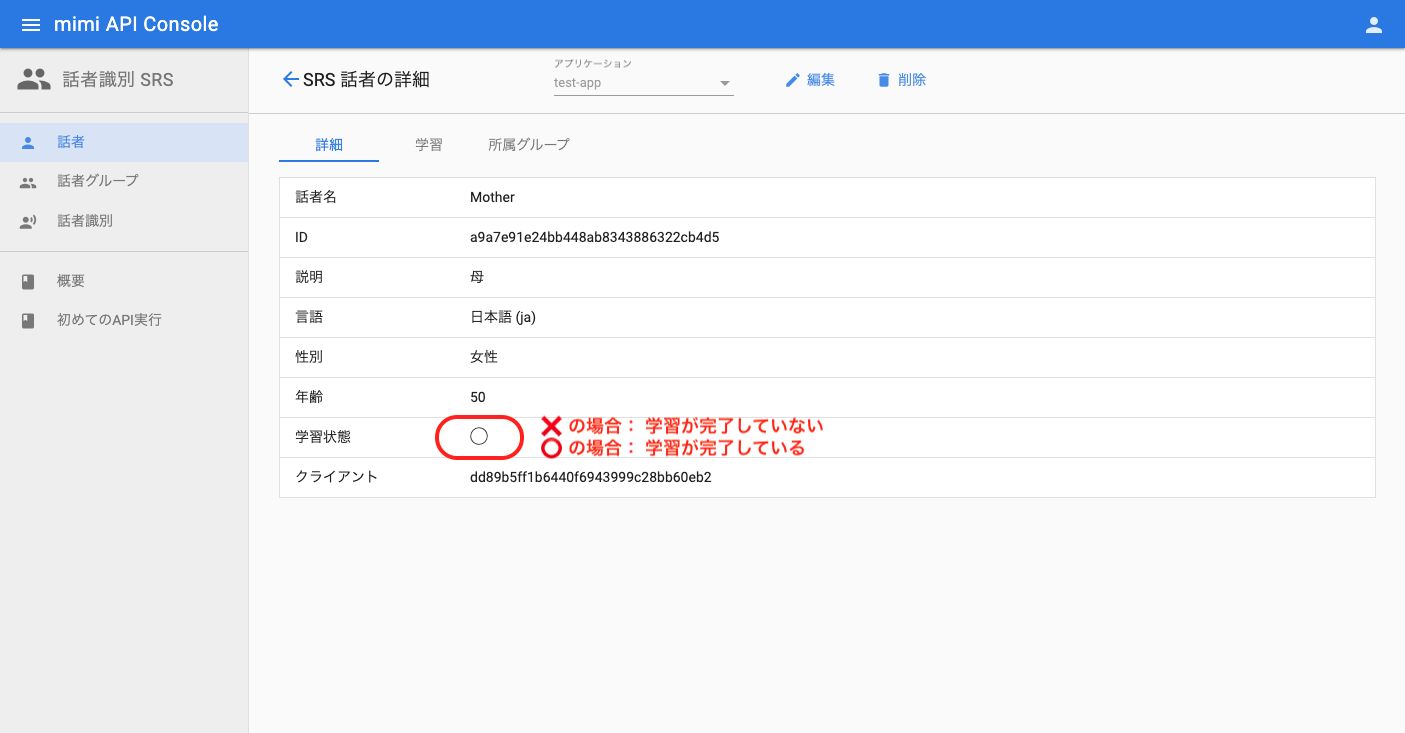
音声データの登録目安について話者識別の精度をあげるために、累計音声長で 2 分以上の音声データを登録することを推奨しています。そうでない場合、学習状態が「○」となっていても、識別精度が低くなる可能性があります。
5 : 話者識別の体験
話者グループに属する全ての話者の学習が完了したら、話者識別の体験が行えるようになります。これは話者識別が、話者グループ単位で識別を行うためです。
話者識別を体験する場合は、左のナビゲーションから「話者識別」を押下し、「マイクで録音」か「ファイルアップロード」で識別させたい音声を入力してください。
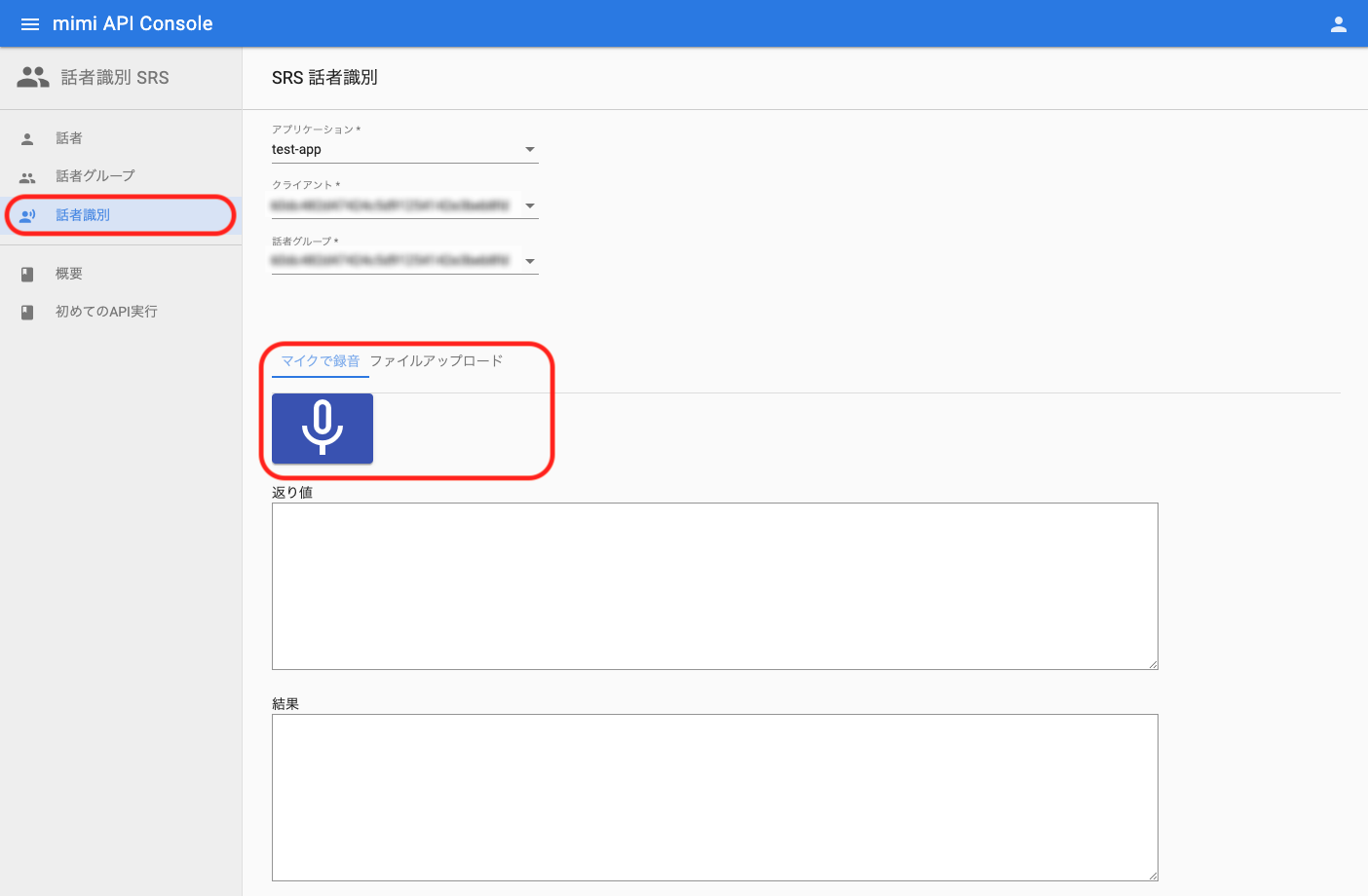
話者識別が完了すると、返り値、結果が表示されます。返り値は話者識別 API の実行結果で、結果は実行結果を分かりやすく示したものです。返り値と結果の見方とについては以下の通りです。
返り値の例
入力した音声データが、誰と認識されていて、その信頼度はどのくらいか、というのが返り値となります。この例では Mother の音声を入力しており、Mother である可能性が高い(84.525%)という返り値になっています。
{
“status”: “recog-finished”, //認識処理完了を示すステータス
“type”: “srs#identification#<speakerGroupId>”, //話者グループID。例の場合、MyFamily の IDとなる。
“response”: {
“speaker”: [
{
“confidence”: 0.84525, //信頼度
“speaker_id”: “<speakerId>” //話者ID。例の場合、Mother の ID となる。
},
{
“confidence”: 0.15475,
“speaker_id”: “” // 値なし = この話者グループに登録されていない話者(非登録話者)となる。
}
]
},
“session_id”: “<sessionId>”
}結果の例
返り値から、誰と認識されていて、その信頼度はどのくらいかのみを抜粋表示しています。
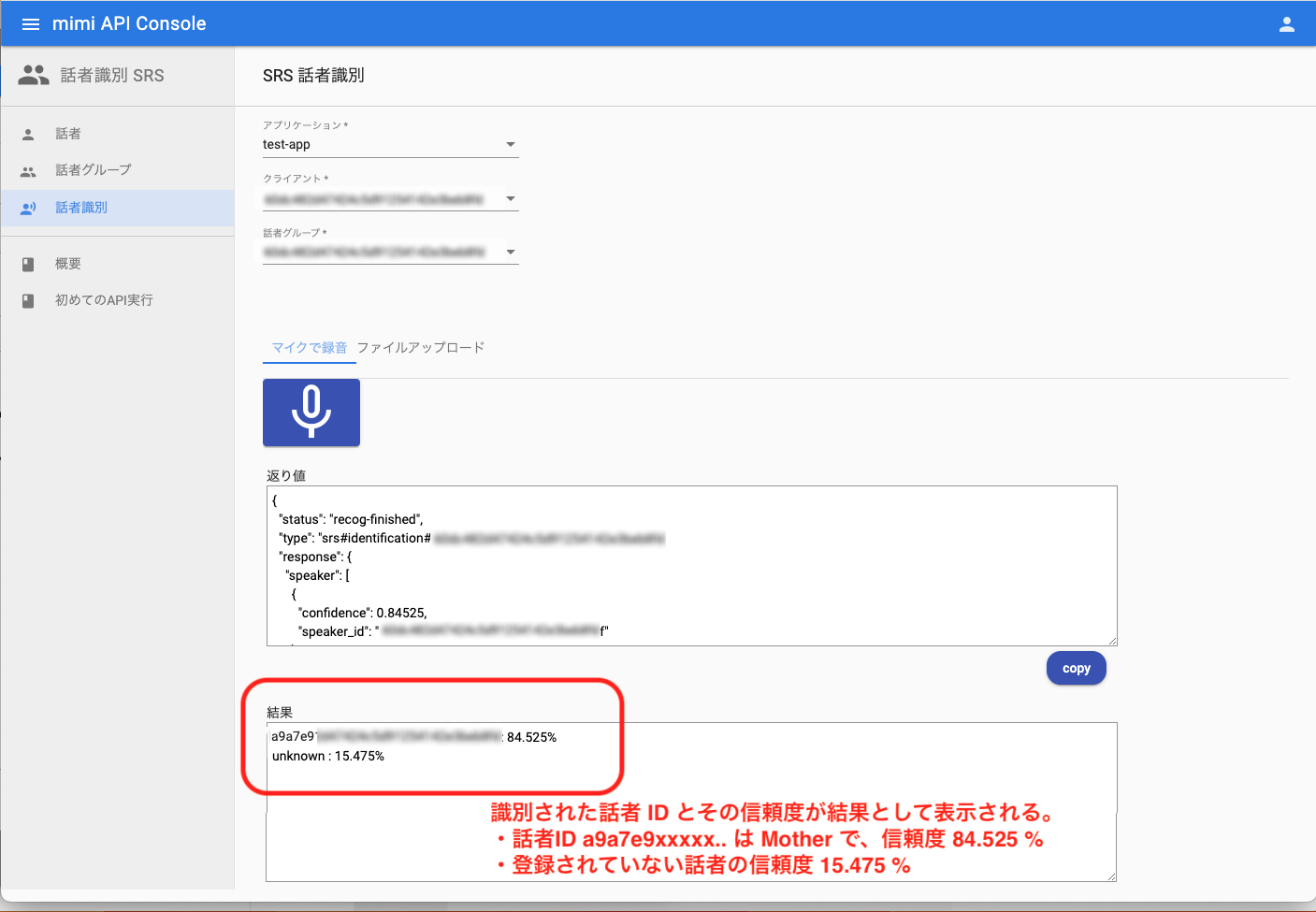
話者識別の精度unknown(非登録話者)として識別される度合いが高い場合、学習データが不足している可能性があります。学習データを追加登録してから話者識別を行ってください。
Updated about 1 year ago